

In this tutorial, we’ll show you how to extract data from Wikipedia pages.
If you’ve ever gone through an online machine learning tutorial, you’re likely to be familiar with standard datasets like Titanic casualties, Iris flowers or customer tips.
These simple, well-structured datasets are great for getting to grips with data science fundamentals. And once you’ve mastered them, you can create your own datasets to investigate anything at all. You might use public APIs to gather this data, such as the ones available for Twitter, Redditor Instagram. Many APIs also have Python packages which make it even easier to access the data you want: Tweepy for Twitter or PRAW for Reddit.
What about when you want to gather data from a website that doesn’t have a nice convenient API? If there’s not much data, it might be possible to just manually copy and paste it — a bit tedious, perhaps, but not too much trouble. And if you just want to extract a table or two from a webpage, you can even use pandas.read_html() to load and parse the page, automatically extracting tables as dataframes.
Crash course: HTML tables
If you are not familiar with HTML, take some time to read about HTML element tags, HTML element attributes and HTML classes. Knowing about these parts of HTML will make it much easier for us to identify and extract the data we want.
Tables in HTML have a nested structure. For a fuller introduction, take a look at the w3schools.com guide. Key points are that nested inside a tableelement are tr elements, which represent the rows. And nested inside the rows are th or td elements, representing the actual cells. th denotes the header row of the table, while td elements will be the standard cells. In the following code, you can see how some elements have class or hrefattributes.
<table class="main-table">
<tr>
<th>Letter</th>
<th>Number</th>
<th>Country</th>
<th>Link</th>
</tr>
<tr>
<td>A</td>
<td>1</td>
<td>Germany</td>
<td><a href="www.url.com">Germany</a>
</tr>
<tr>
<td>B</td>
<td>2</td>
<td>France</td>
<td><a href="www.url.com">France</a>
</tr>
</table>
Which generates this table:
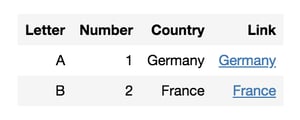
Tables can be much more complex than this, as we will see, but this nested structure is common to them all.
Extracting tables from HTML is easy with pandas:
In [1]:
import pandas as pd
data = pd.read_html('https://en.wikipedia.org/wiki/List_of_cities_in_the_United_Kingdom')
print(f'Extracted {len(data)} table/s')
data[0]
Extracted 4 table/s
Out[1]:
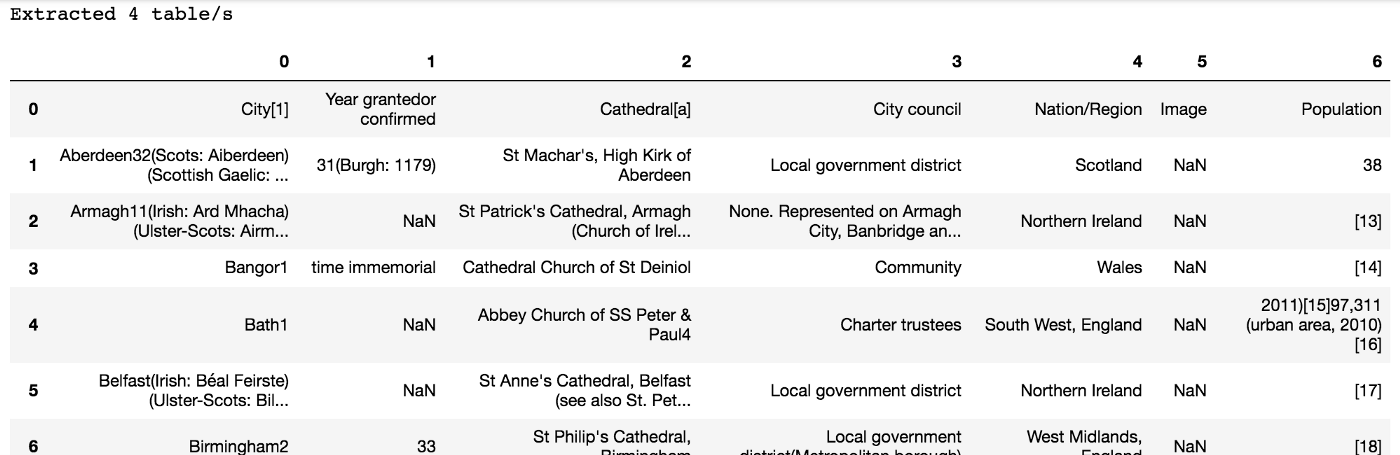
If we look at the first item extracted, it’s the table showing information about all the cities in the UK. However, this would need cleaned up a bit — there are no column names, plus there is a lot of extraneous text such as footnote references and so on. This data is not very useable in its current format.
Crawling
Imagine you want to not only get a list of all the cities in the UK, but extract some information about them from Wikipedia. And you don’t want to click on anything! We’ll use requests and beautifulsoup to do this. Wikipedia articles like these contain a vast amount of information, but we will focus on the following:
- Which country it is in
- The current population
- A list of other Wikipedia pages the city article links to in its introduction
The first three items on this list will require extracting data from tables. The last item will extract data that is not in a table, which pandas would not be able to extract.
The process looks like this:
- Generate a list of Wikipedia URLs for the cities of the UK
- Access each URL and extract the above information
- Save the extracted information to disk for analysis later on
Extracting the URLs from a Wikipedia page
Although we can use pandas to get the text of the table of cities, it doesn’t get the URLs. Another option would be to just copy and paste the links from the page, but that almost defeats the point of knowing Python. We can automate this process.
There are some packages that can do this for us if we have some knowledge about how HTML is structured:
- requests to get the HTML. This is a great package for accessing URLs and is incredibly simple to use
- beautifulsoup to parse that HTML and extract the items we want. Also very simple to use, but it helps to know a bit about HTML beforehand
In [2]:
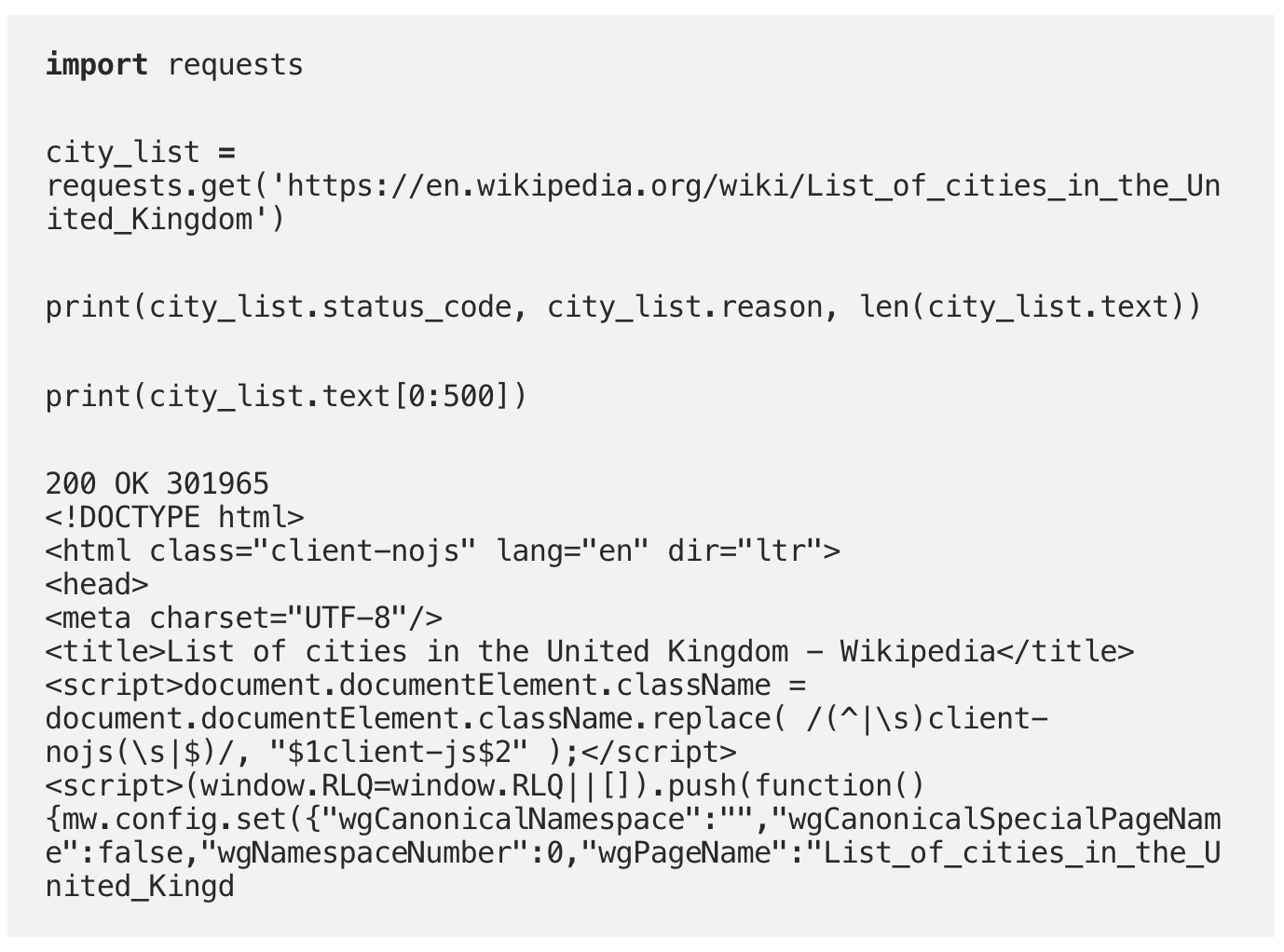
The city_list variable contains all the HTTP data for the URL we accessed. The request was successful, as a status code of 200 was returned, and around 300k characters of HTML were retrieved.
Before information can be extracted from that HTML, it must be parsed. This lets us refer to elements in the data according to various properties (such as class or attribute) and is much easier than using regular expressions.
At this point, we need to find the “List of cities” table in the HTML. This can be done by viewing the page source (available from the right-click menu in most web browsers) and searching for <table to find the start of any tables. This page contains four but the one we want looks like this:
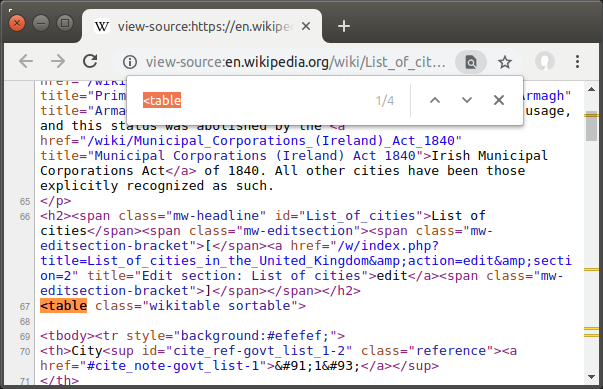
This table is of the class wikitable sortable. We can use beautifulsoup to parse the HTML and search for all table elements with a class of wikitable sortable.
In [3]:

Luckily, there is only one table with that class, so there is no need to examine all the results and find the correct item. We can just use the single item in the list that the find_all() function returns.
HTML tables are organised by rows, which are tr elements inside the parent table. These can be extracted using find_all() again.
In [4]:

There are only 69 cities in the UK, so it looks like we’ve got the data we need plus an extra header row.
The cells in each row are td elements. The exception is the header row, which are th. Again, these can be extracted from each row using find_all(). We only want the first column of the table, which has the links to the cities' pages. This link is an a element, which can be extracted just like the other elements. It's clear from the HTML source that the first link is what we want. Once this has been found, it is the href attribute that needs to be extracted - this is the actual link. Finally, the links will be relative rather than absolute, so it will be necessary to prepend the domain name onto them.
In [5]:

Out[5]:

Now that we have our links, we can loop through them and extract required information from each page. In the following part, I’ll use the example of Leeds to show you how to use the structure of HTML to extract what we need.
Which country is the city in?
This information can be found in the info box to the right of the Wikipedia page, next to the cell named “Constituent country”.
Inspecting the HTML source shows that this is inside a tr of class mergedrow. There is a header th cell with the text "Constituent country" and the data we want is in the text of the adjacent td cell.
(Note: When trying to examine the structure of the HTML, you will probably find it useful to view it in an editor that does syntax highlighting and will prettify the code to show the nested structure. Many text editors, such as SublimeText, have plugins that will do this if they do not do it natively.)
To extract this, we can search for all the mergedrow elements. Then we loop through all the pairs until we find what we want.
In [6]:

Testing
This works for Leeds, but what about the other cities? Unfortunately, the Wikipedia pages are not entirely consistent in how they structure their HTML. It will be necessary to check the output.
In [7]:

So one city is missing the data we need. That’s easily checked and it seems the problem is that the Wikipedia entry for the city of Newport in Wales uses the word “part” instead of “country”
(Note: this is a very common problem when scraping data from HTML! You think you’ve figured it all out and then the edge cases start popping up, where some tiny difference makes it impossible to extract what you want.)
This is easily fixed by checking for “part” and “country”:
In [8]:
country_data = {}
for c in links:
name = c.split('/')[-1]
# Get the city name from the URL
city = requests.get(c)
city = bs(city.text, 'lxml')
rows = city.find_all('tr', {'class':'mergedrow'})
for r in rows:
if len(r) == 2:
header, cell = r
if 'country' in header.text.lower() or 'part' in header.text.lower():
country_data[name] = cell.text.strip()
# No need to keep looking once a match is found
break
if country_data.get(name):
# Evaluates as True only if key in dictionary
pass
else:
print(f'Did not get data for {name}!')
print(f'Got data for {len(country_data)} of {len(links)} cities.')
# If a country was found for the city, there will be a dictionary entry for it.
Got data for 69 of 69 cities.
What is the current population?
The HTML source shows that this is going to be trickier: the population data is not neatly marked with a convenient header in the table. From looking at the entry for Leeds:

The data we want is inside a td element but this has no useful attributes we can use to identify it. However, the preceding tr element, with class mergedtoprow, contains the word "Population". So we can target that and get its next sibling in the HTML structure. This is the tr with mergedrow: then we just need to get its children and select the td element, which we know (from the HTML) is the second child in the returned iterator. The text can be extracted from this and cleaned up.
This time, let’s check all the cities at once and clean up as we go.
In [9]:
population_data = {}
for c in links:
name = c.split('/')[-1]
# Get the city name from the URL
city = requests.get(c)
city = bs(city.text, 'lxml')
rows = city.find_all('tr', {'class':'mergedtoprow'})
population = None
for r in rows:
if 'Population' in r.text:
sibling = r.next_sibling
td_child = list(sibling.children)[1]
population = td_child.text.strip()
# Remove linebreaks from start/end
population = population.split()[0]
# Get the first item before a space
population_data[name] = population
break
print(name, population)
Aberdeen 3,505.7/km2
Armagh None
Bangor,_Gwynedd None
Bath,_Somerset None
Belfast None
Birmingham 1,137,100
City_of_Bradford 534,800
Brighton_and_Hove 288,200
Bristol 459,300
Cambridge 124,900
City_of_Canterbury 164,100
Cardiff 361,468[1]
City_of_Carlisle 108,300
City_of_Chelmsford 176,200
Chester None
Chichester None
Coventry 360,100
Derby 248,700
Derry None
Dundee 148,270
Durham,_England 48,069
Edinburgh 464,990
Ely,_Cambridgeshire None
Exeter 128,900
Glasgow 621,020[1]
Gloucester 129,100
Hereford None
Inverness None
Kingston_upon_Hull 260,700
City_of_Lancaster 142,500
City_of_Leeds 784,800
Leicester 329,839[1]
Lichfield None
Lincoln,_England 97,541[1]
Lisburn None
Liverpool 491,500
City_of_London 9,401
Manchester 545,500
Newcastle_upon_Tyne 295,800
Newport,_Wales 151,500
Newry None
Norwich 141,300
Nottingham 321,500
Oxford 151,906
Perth,_Scotland None
City_of_Peterborough 198,900
Plymouth 263,100
Portsmouth 205,100
City_of_Preston,_Lancashire 141,300
Ripon None
City_and_District_of_St_Albans (of
St_Asaph None
St_Davids None
City_of_Salford 251,300
Salisbury None
City_of_Sheffield 577,800
Southampton 236,900
Stirling None
Stoke-on-Trent 255,400
City_of_Sunderland 277,962
Swansea Unitary
Truro None
City_of_Wakefield 340,800
Wells,_Somerset None
City_of_Westminster 244,800
City_of_Winchester 123,900
Wolverhampton 259,900
Worcester 101,328
City_of_York 208,200
Oh dear! It looks like we’ve grabbed the wrong HTML element for some cities and instead got the area, or failed to get anything at all.
To fix this, we need to dig around in the HTML for cities that failed and edit our code. Here’s what the result of that should look like.
In [10]:
population_data = {}
for c in links:
name = c.split('/')[-1]
# Get the city name from the URL
city = requests.get(c)
city = bs(city.text, 'lxml')
population = None
if name in ['Derry']:
rows = city.find_all('tr')
for r in rows:
if 'Population' in r.text:
population = r.find_all('li')[0].text
break
elif name in ['Aberdeen', 'Armagh', 'Bangor,_Gwynedd', 'Bath,_Somerset', 'Belfast', 'Chester','Chichester', 'Hereford', 'Inverness', 'Ely,_Cambridgeshire', 'Lichfield', 'Lisburn', 'Newry', 'Perth,_Scotland', 'Ripon', 'Stirling', 'Truro', 'Wells,_Somerset']:
rows = city.find_all('tr')
for r in rows:
if 'Population' in r.text:
children = list(r.children)
population = children[1].text.replace('\n', ' ').strip()
break
else:
rows = city.find_all('tr', {'class':'mergedtoprow'})
for r in rows:
if 'Population ' in r.text:
population = r.next_sibling.text.replace('\n', ' ').strip()
break
population_data[name] = population
In [11]:
for name, population in population_data.items():
if population:
print(f'{name:<30} : {population:}')
else:
print(f'!! Nothing found for {name}')
Aberdeen : 196,670[1] – City proper
Armagh : 14,749 (2011 Census)
Bangor,_Gwynedd : 18,810 (2011 census)
Bath,_Somerset : 88,859 [1]
Belfast : City of Belfast:340,200 (2017)[2] Urban Area:483,418 (2016)[3]Metropolitan area:671,559 (2011)[4]
Birmingham : • City 1,137,100
City_of_Bradford : • Total 534,800 (Ranked 6th)
Brighton_and_Hove : • City and unitary authority 288,200
Bristol : • City and county 459,300 (Ranked 10th district and 43rd ceremonial county)
Cambridge : • City and non-metropolitan district 124,900 (ranked 183rd)
City_of_Canterbury : • Total 164,100
Cardiff : • City & County 361,468[1]
City_of_Carlisle : • Total 108,300 (Ranked 221st)
City_of_Chelmsford : • Total 176,200
Chester : 118,200 [1]
Chichester : 26,795 [2] 2011 Census
Coventry : • City and Metropolitan borough 360,100 (Ranked 15th)
Derby : • City and Unitary authority area 248,700
Derry : Derry: 85,016
Dundee : • Total 148,270
Durham,_England : • Total 48,069 (urban area)[1]
Edinburgh : • City and council area 464,990 – Locality [1] 513,210 – Local Authority Area[2]
Ely,_Cambridgeshire : 20,112
Exeter : • Total 128,900
Glasgow : • City 621,020[1]
Gloucester : • Total 129,100
Hereford : 58,896 [1]
Inverness : 63,780 [1]
Kingston_upon_Hull : • City 260,700 (Ranked 58th)
City_of_Lancaster : • Total 142,500
City_of_Leeds : • Total 784,800 (Ranked 2nd)
Leicester : • City 329,839[1]
Lichfield : 32,219 (2011)[2]
Lincoln,_England : • City and Borough 97,541[1]
Lisburn : 120,465 surrounding areas
Liverpool : • City 491,500
City_of_London : • City 9,401
Manchester : • City 545,500
Newcastle_upon_Tyne : • City 295,800 (ranked 40th district)
Newport,_Wales : • Total 151,500 (Ranked 7th)
Newry : 26,967 (2011)[4]
Norwich : • City 141,300 (ranked 146th)
Nottingham : • City 321,500
Oxford : • City and non-metropolitan district 151,906 (2,011)[1]
Perth,_Scotland : 47,180 (est. 2012), excluding suburbs[3]
City_of_Peterborough : • Total 198,900
Plymouth : • Total 263,100
Portsmouth : • City & unitary authority area 205,100 (Ranked 76th)[2]
City_of_Preston,_Lancashire : • City & Non-metropolitan district 141,300 (Ranked 146th)
Ripon : 16,702 (2011 census)[1]
City_and_District_of_St_Albans : • Rank (of 326)
!! Nothing found for St_Asaph
!! Nothing found for St_Davids
City_of_Salford : • Total 251,300 (Ranked 65th)
!! Nothing found for Salisbury
City_of_Sheffield : • City 577,800 (Ranked 3rd)
Southampton : • City and unitary authority area 236,900 (Ranked 57)
Stirling : 36,142 Census 2011 [1]
Stoke-on-Trent : • City 255,400
City_of_Sunderland : • Total 277,962
Swansea : • Total Unitary Authority area: 245,500, Ranked 2nd Urban area within Unitary Authority: 179,485 Wider Urban Area: 300,352 Metropolitan Area: 462,000 Swansea Bay City Region: 685,051
Truro : 18,766 [1]
City_of_Wakefield : • Total 340,800
Wells,_Somerset : 10,536 (2011)[1]
City_of_Westminster : • Total 244,800
City_of_Winchester : • Total 123,900
Wolverhampton : • Total 259,900 (59th)
Worcester : • Total 101,328
City_of_York : • Total 208,200 (Ranked 84th)
The structure of the HTML fell into three distinct categories. Derryhad a list structure inside a table cell. Several cities had rows without the mergedtoprowclass name. But most used the same structure as Leeds.
Some cities did not actually have population data listed inside tables (e.g. St.Asaph, St.David). This will likely have to be added manually.
A final issue is that the data extracted is still very messy. Ideally it would be nicely formatted as integers. However, a few regular expressions will fix that all up.
Extracting links
The final bit of information we’ll extract is all the links contained in the introduction for each city. In general, the introduction is the text that appears before the table of contents. Each paragraph is wrapped in a p element in HTML and the table of contents has an id of toc. Because id must be unique in an HTML document, it will be easy to identify the TOC. The Wiki pages we are working with here have the general structure:
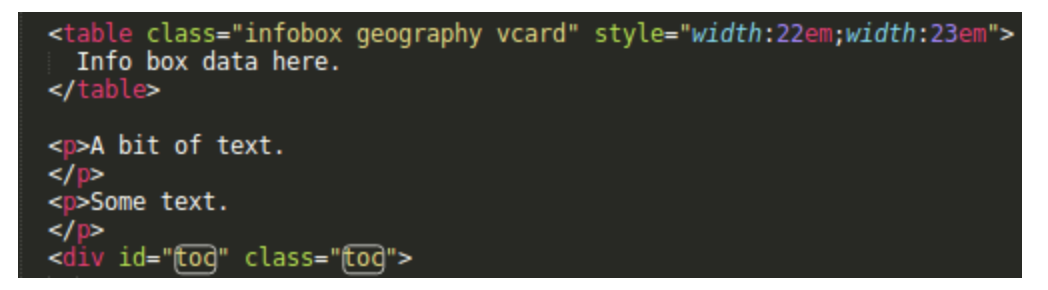
First comes the infobox table, which we’ve already extracted data from. Then a series of paragraphs of text. Then a div containing the table of contents. All we need to do is loop through the p elements and keep checking to see if that element has a sibling below it on the page which has a particular id and, if so, stop looping through the paragraphs. And for each paragraph, we'll extract the a elements to get the links.
In [12]:
intro_data = {}
for c in links:
name = c.split('/')[-1]
# Get the city name from the URL
city = requests.get(c)
city = bs(city.text, 'lxml')
intro_links = []
introduction_paragraphs = []
all_paragraphs = city.find_all('p')
for p in all_paragraphs:
# Find all the links inside a paragraph
found_links = set([l.attrs['href'] for l in p.find_all('a')])
intro_links.extend([i for i in found_links if i.startswith('/wiki/') and ':' not in i])
# Only want links that go to Wikipedia pages, but exclude Help: pages
next_sibling = p.find_next_sibling()
# Check the next item in the HTML structure that comes after this paragraph
if next_sibling:
# If it exists...
if next_sibling.get('id') == 'toc':
# And if it has the toc id
break
# Then have eached TOC, so stop processing further paragraphs.
intro_data[name] = intro_links
In [13]:
for city, link_list in list(intro_data.items())[0:10]:
print(f'{len(link_list):>3} links for {city}')
print(intro_data['Aberdeen'][0:5])
23 links for Aberdeen
23 links for Armagh
12 links for Bangor,_Gwynedd
41 links for Bath,_Somerset
20 links for Belfast
47 links for Birmingham
53 links for City_of_Bradford
8 links for Brighton_and_Hove
58 links for Bristol
32 links for Cambridge
['/wiki/List_of_towns_and_cities_in_Scotland_by_population', '/wiki/City_status_in_the_United_Kingdom', '/wiki/List_of_urban_areas_in_the_United_Kingdom', '/wiki/Local_government_in_Scotland', '/wiki/Scots_language']
Putting it all together
With the code written for extracting the three required kinds of information, we can put together a little script that will do everything.
In [14]:
import requests
from bs4 import BeautifulSoup as bs
links = [] # Store links to city Wiki pages
city_list = requests.get('https://en.wikipedia.org/wiki/List_of_cities_in_the_United_Kingdom')
city_list = bs(city_list.text, "lxml")
table = city_list.find_all('table', {'class':'wikitable sortable'})
table = table[0]
# Download and parse HTML list of UK cities
for row in table_rows:
cells = row.find_all('td')
if cells:
link = cells[0].find_all('a')[0]
link = link.attrs['href']
links.append(f'https://en.wikipedia.org{link}')
else:
# We found "th" header cells, instead of "td"
pass
country_data = {} # Store info about which country each city is in
population_data = {} # Store info about the population of each city
intro_data = {} # Store info about links in city introduction text
for c in links:
name = c.split('/')[-1]
# Get the city name from the URL
city = requests.get(c)
city = bs(city.text, 'lxml')
# Download and parse the HTML
rows = city.find_all('tr', {'class':'mergedrow'})
# Access the rows of the table we want
for r in rows:
if len(r) == 2:
header, cell = r
if 'country' in header.text.lower() or 'part' in header.text.lower():
country_data[name] = cell.text.strip()
# No need to keep looking once a match is found
break
population = None
if name in ['Derry']:
rows = city.find_all('tr')
for r in rows:
if 'Population' in r.text:
population = r.find_all('li')[0].text
break
elif name in ['Aberdeen', 'Armagh', 'Bangor,_Gwynedd', 'Bath,_Somerset', 'Belfast', 'Chester', 'Chichester', 'Hereford', 'Inverness', 'Ely,_Cambridgeshire', 'Lichfield', 'Lisburn', 'Newry', 'Perth,_Scotland', 'Ripon', 'Stirling', 'Truro', 'Wells,_Somerset']:
rows = city.find_all('tr')
for r in rows:
if 'Population' in r.text:
children = list(r.children)
population = children[1].text.replace('\n', ' ').strip()
break
else:
rows = city.find_all('tr', {'class':'mergedtoprow'})
for r in rows:
if 'Population ' in r.text:
population = r.next_sibling.text.replace('\n', ' ').strip()
break
population_data[name] = population
intro_links = []
introduction_paragraphs = []
all_paragraphs = city.find_all('p')
for p in all_paragraphs:
# Find all the links inside a paragraph
found_links = set([l.attrs['href'] for l in p.find_all('a')])
intro_links.extend([i for i in found_links if i.startswith('/wiki/') and ':' not in i])
# Only want links that go to Wikipedia pages, but exclude Help: pages
next_sibling = p.find_next_sibling()
# Check the next item in the HTML structure that comes after this paragraph
if next_sibling:
# If it exists...
if next_sibling.get('id') == 'toc':
# And if it has the toc id
break
# Then have eached TOC, so stop processing further paragraphs.
intro_data[name] = intro_links
Collating the data
The extracted data is in three dictionaries, country_data, population_data, intro_data. There are a variety of ways to structure this for further analysis.
In [15]:
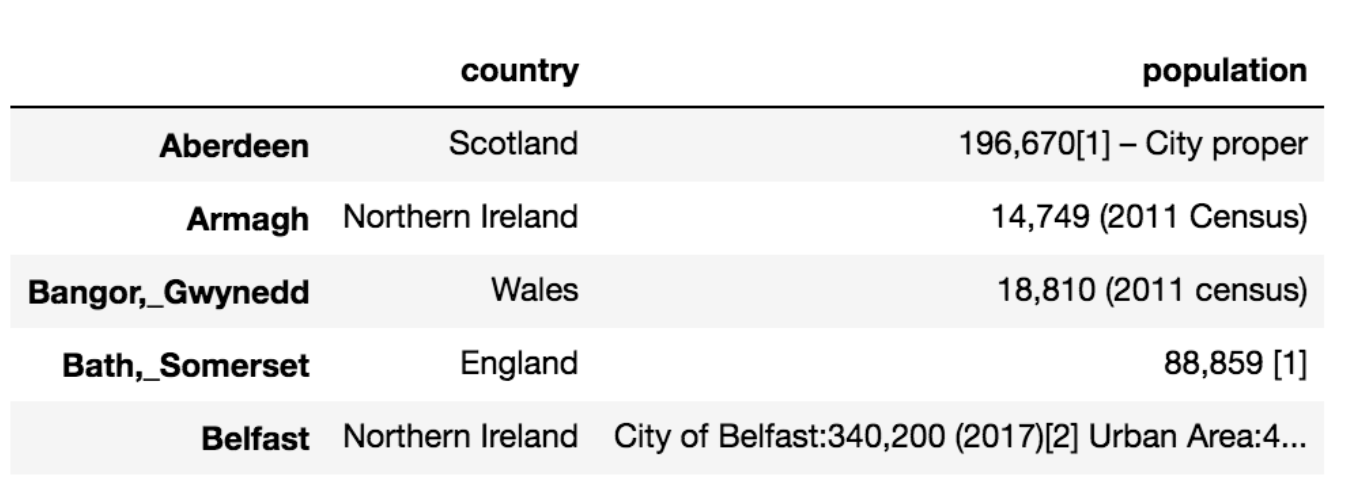
Out[15]:
Using the data
For the link data, it might be interesting to visualise it as a graph. That will make it possible to see how cities are connected in terms of the concepts and ideas used to define them in Wikipedia.
First, we’ll get the data into a suitable format for graphing, then save it for use in Gephi.
In [43]:
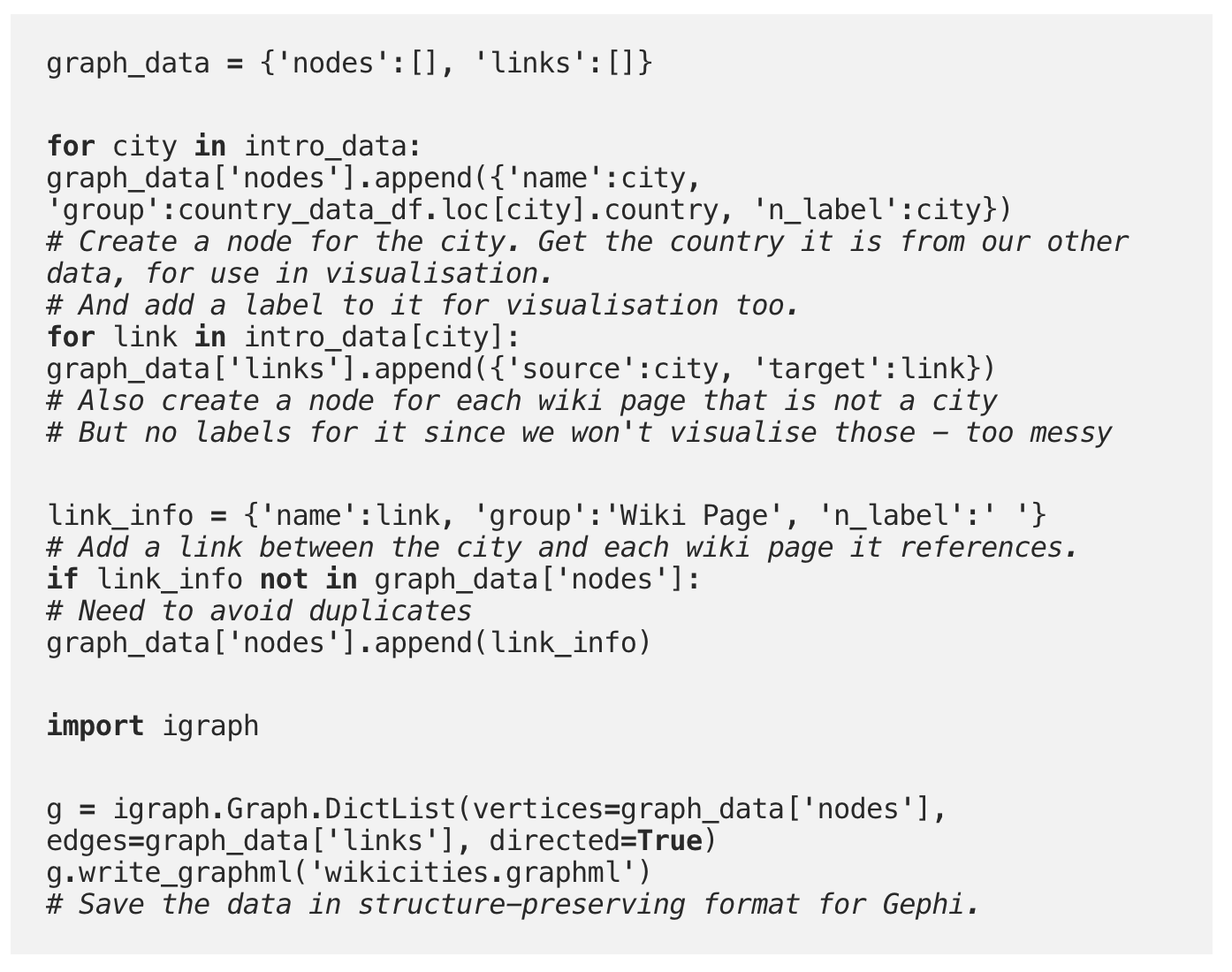
The data can then be loaded into Gephi and visualised. I highly recommend playing around with it! It makes is very easy to arrange the layout of the graph as well as apply colours and labels.
Below, you can see that I’ve coloured the city nodes/labels according to the country they are in. Edges are coloured according to the colour of their source node. It’s clear that cities in the same country share a lot of links in common.
Next steps
- Try cleaning up the population data and using it in Gephi to set the size of the nodes for cities, so that larger cities appear bigger in the graph.
- Want to practice working with HTML in beautifulsoup? Try extracting data from toscrape.com/, which has lots of different types of webpage to work with.
- If you want to extend the code above to not only follow the links on the List of UK cities page, but also follow links from those links, take a look at the scrapy framework, which makes it easy to recursively crawl a website.
-1.png)
Enquire now
Fill out the following form and we’ll contact you within one business day to discuss and answer any questions you have about the programme. We look forward to speaking with you.
