

Introduction
It’s no doubt that eCommerce has been an uprising giant in the retail space, across multiple verticals.
In 2021 alone, retail e-commerce sales amounted to approximately 4.9 trillion U.S. dollars worldwide. This figure is forecast to grow by 50% over the next four years, reaching about 7.4 trillion dollars by 2025. As technology and consumers' tastes have evolved over the years, the user experience (UX) of consumers has played a pivotal role in staying relevant and competitive in the market space. One of the drivers behind this is Data Science.

Masses of cross-platform data
The nature of eCommerce sees customers going through multiple touch-points; from clicking on an advertisement, to clicking through various products of interest, right through to making a purchase and leaving a product review.
The data from these integrated platforms mean that eCommerce retailers sit on a goldmine of data, ready to be mined and provide actionable insight to decision-makers— helping retailers to reduce their bottomline through the effective and strategic targeting of new and existing customers.
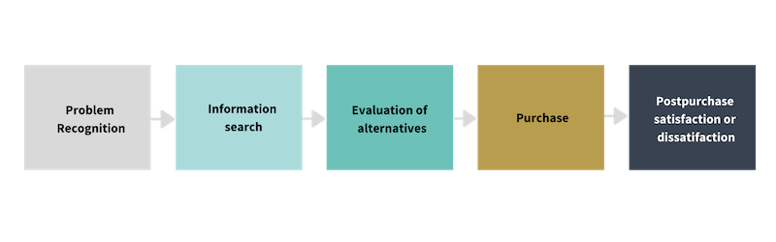
Figure one: decision-making process consumers go through when purchasing online
Data amassed from the various platforms can help build a picture around the retailer's consumer personas, their purchasing habits, and which mediums are effective at moving them along the stages of the decision-making process and be successfully acquired as a customer — as well as how long this process generally takes.
Equally, this data is particularly valuable for providing insight into which prompts and steps can be taken to prevent customer churn and basket abandonment.
Data science in retail creates a commercially-minded collaborative environment to discover and realise new opportunities.
Applications of Data Science to eCommerce businesses
Data Science serves to help eCommerce retailers with two strategic objectives:
1. The acquisition of customers
2. The retention of customers
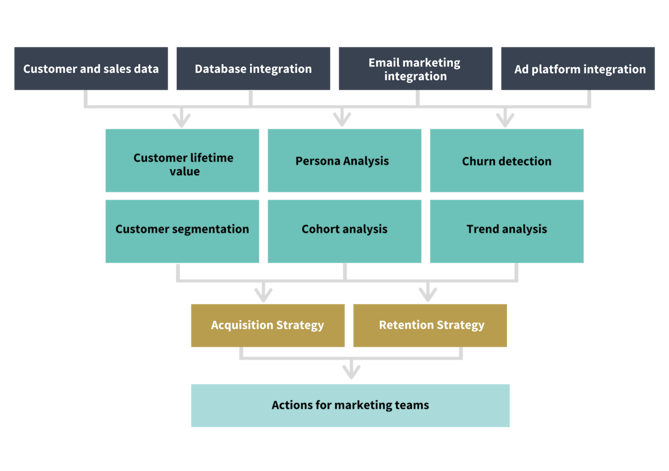
Figure two: Data Science in practice within eCommerce retailers
Applications of Data Science in eCommerce
Predicting customer churn
Customer churn - also known as attrition - occurs when customers stop doing business with a retailer, or when a subscriber cancels their subscription. A predictive churn model can help identify which of your customers will stop engaging with you and why.
Examples of churn can also include:
- Closure of an account
- Non-renewal of a contract or service agreement
- The decision to shop at another store
- Use of an alternative service provider
Segmenting and highlighting your star customers
Depending on a variety of attributes and behaviours, retailers can highlight which consumers require more nurturing and bespoke pricing strategies to prompt them to checkout their items using customer segmentation models.
For example, retailers could apply a simplistic RFM scoring model, taking into account the days since the consumers' last purchase (recency), the total number of purchases (frequency) and total money they've spent (monetary value) to classify them. From there, retailers can strategically interact with consumers and suggest offers or prices which typically convert those with similar profiles to them.
Retailers can also use customer lifetime value (CLV) modeling to understand which channels their most valuable customers are coming from, what types of engagement are associated with them, and then incentivise these behaviours and invest more into channels which deliver the best return on investment (ROI).
👉RECOMMENDED READING: 
Driving sales with intelligent product recommendations
eCommerce retailers are able to apply different algorithms and techniques to enable their recommender systems to generate recommendations.
The most popular ones are:
- Association rules (recommendations based on their presence alongside other products)
- Collaborative filtering (recommendations based on customer profiles, ratings and reviews)
- Content-based filtering (where product recommendations are based on an analysis of products and finding similarities with other active users)
- Hybrid filtering (a select mix of the above)
Extracting useful information from customer reviews
Retailers are able to use Natural Language Processing (NLP) techniques to scrape their customers' reviews and extract useful information about why they're leaving reviews are positive or negative - enabling them to prioritise any feature or product updates, in order to maximise satisfaction/user experience.
Forecasting demand
Retailers are able to run time series machine learning models, allowing them to:
- Optimise staffing levels to ensure they have the optimum amount of resource to fulfil orders
- Manage inventory more effectively
- Forecast future product demand for their current product offering and new product launches
Optimising prices
Applying Machine Learning in eCommerce stores is an effective approach to determining the optimum price for each product and service, especially when compared to the traditional method of pushing a product out with a set price, only to apply aggressive markdowns to products not performing as well due to high price points.
Price optimisation machine learning models are able to take into account:
- Demand
- Competition
- Costs
- Company objectives
- The weather/season
These factors ensure that the initial, best, discounted and promotional prices that are determined by the machine learning models are optimal.
Looking for Data Science training for your team?
👉RECOMMENDED READING: 
Case study: Carrefour

a) Predict the churn of customersCarrefour were looking for training to develop their Data Science team's knowledge of the advanced Data Science tools and techniques they're able to use, in order for them to:
b) Enhance their customers' shopping experience by enabling greater personalisation of suggested products and communications.
To approach the skill gaps presented to us, we were able to implement a bespoke Data Science, outlined below:
- Machine Learning
- Ensemble models - Technical
- Writing production-ready code - Object-Oriented Programming
- Classes, method, state
- Inheritance
- Anti-patterns
- Single Responsibility Principle
- Coupling and Cohesion
- Encapsulation - Functional Programming constructs in Python
- Filter, map, reduce, zip, izip, partial
- List and Dict comprehensions
- Mutable and immutable objects - Modules and Packages
- Packages, sub-packages, modules, __init__.py
- Project structure, imports
- Installable packages, setup.py, command-line entrypoints - Unit Testing in Python
- Unittest, assertions, set up
- Testing best practices - Code Quality and Tools
- Pylint, pep8, mccabe
- Writing Pythonic code
Training outcomes
Alexandra Tcheng, Data Scientist at Carrefour, said:
“We really enjoyed the first day, where we explored decision trees and the ways we could use them.” “We especially liked the fact that the training focused on industry best practices whilst building upon modularised training. We found the hands-on exercises helpful as they enabled us to see how learnings could be applied practically on real projects.” “The participants greatly appreciated that the trainers were both knowledgable and approachable so that everyone felt at ease to ask any questions they had. We would happily recommend Cambridge Spark as a training provider in the Data Science space.“
Interested in training for your teams?
Whether you're looking to train 5 people or 100 people, we have a variety of scalable training solutions to help you address a wide spectrum of training needs within the fields of Data Science, Artificial Intelligence, or Software Engineering.
About Carrefour
Over the past 40 years, the Carrefour group has grown to become one of the world’s leading distribution groups. The world’s second-largest retailer and the largest in Europe, the group currently operates four main grocery store formats: hypermarkets, supermarkets, cash & carry and convenience stores. The Carrefour group currently has over 9,500 stores, either company-operated or franchises.
Get in touch with a Cambridge Spark
